
Los puntos de referencia están luchando por mantenerse al día con las capacidades avanzadas del modelo de IA y el proyecto Humanity’s Last Exam quiere su ayuda para solucionar este problema.
El proyecto es una colaboración entre el Centro para la Seguridad de la IA (CAIS) y la empresa de datos de IA Scale AI. El proyecto tiene como objetivo medir qué tan cerca estamos de lograr sistemas de IA de nivel experto, algo que los puntos de referencia existentes no son capaces de hacer.
OpenAI y CAIS desarrollaron el popular punto de referencia MMLU (Massive Multitask Language Understanding) en 2021. En aquel entonces, dice CAIS, “los sistemas de IA no funcionaron mejor que los aleatorios”.
El impresionante rendimiento del modelo o1 de OpenAI ha “destruido los puntos de referencia de razonamiento más populares”, según Dan Hendrycks, director ejecutivo de CAIS.
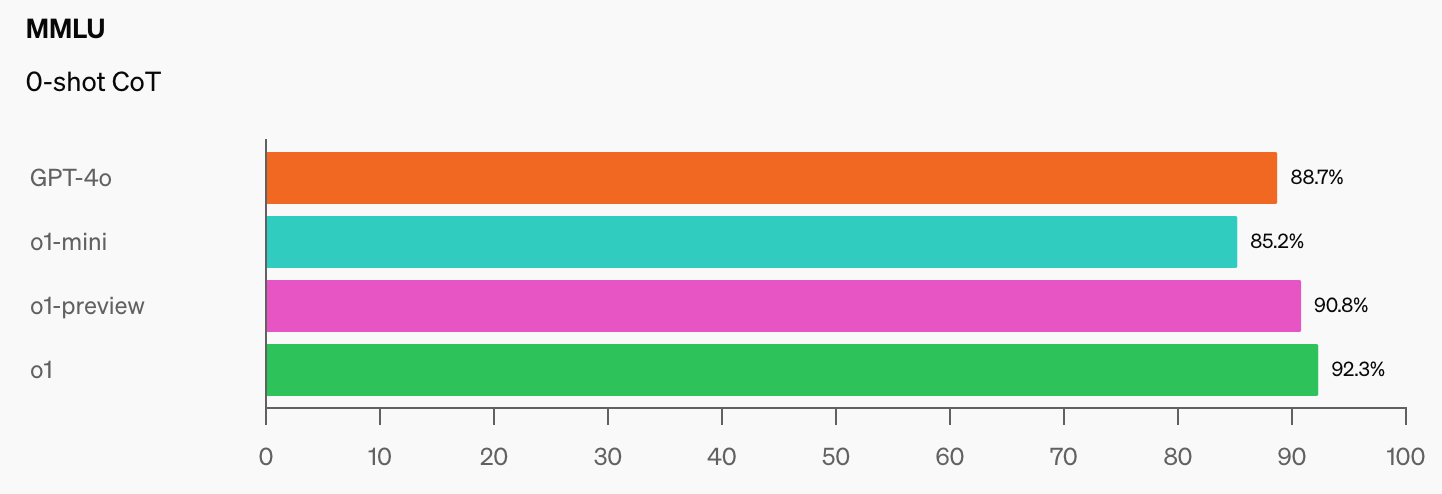
Una vez que los modelos de IA alcancen el 100% en la MMLU, ¿cómo los mediremos? CAIS dice: “Las pruebas existentes ahora se han vuelto demasiado fáciles y ya no podemos seguir bien los desarrollos de la IA, o qué tan lejos están de alcanzar el nivel de expertos”.
Cuando vea el salto en las puntuaciones de referencia que o1 sumó a las ya impresionantes cifras de GPT-4o, no pasará mucho tiempo antes de que un modelo de IA supere la MMLU.
Esto es objetivamente cierto. pic.twitter.com/gorahh86ee
– Ethan Mollick (@emollick) 17 de septiembre de 2024
El último examen de la humanidad pide a las personas que envíen preguntas que realmente lo sorprenderían si un modelo de inteligencia artificial entregara la respuesta correcta. Quieren preguntas de examen de nivel de doctorado, no del tipo ‘cuántas R hay en fresa’ que hacen tropezar a algunos modelos.
Scale explicó que “a medida que las pruebas existentes se vuelven demasiado fáciles, perdemos la capacidad de distinguir entre los sistemas de inteligencia artificial que pueden aprobar los exámenes de pregrado y aquellos que realmente pueden contribuir a la investigación de vanguardia y la resolución de problemas”.
Si tiene una pregunta original que podría obstaculizar un modelo avanzado de IA, entonces podría agregar su nombre como coautor del artículo del proyecto y compartir un fondo común de $500,000 que se otorgará a las mejores preguntas.
Para darle una idea del nivel al que apunta el proyecto, Scale explicó que “si un estudiante universitario seleccionado al azar puede entender lo que se le pregunta, probablemente sea demasiado fácil para los LLM de hoy y de mañana”.
Existen algunas restricciones interesantes sobre los tipos de preguntas que se pueden enviar. No quieren nada relacionado con armas químicas, biológicas, radiológicas, nucleares o ciberarmas utilizadas para atacar infraestructuras críticas.
Si cree que tiene una pregunta que cumple con los requisitos, puede enviarla aquí.






